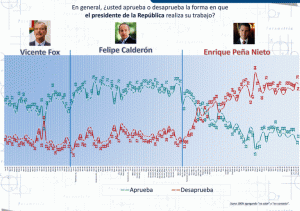
Es probable que el contexto de la elección presidencial de 2006 no ayude mucho a realizar una buena medición en términos de encuestas electorales. Las expectativas en torno a éstas rebasan por un amplio margen su capacidad de precisión. En un escenario de competencia electoral cerrada, en el cual las diferencias entre las tres principales fuerzas electorales no sean de más de cinco puntos porcentuales, lo más probable es que las mediciones no coincidan. Si bien no es un hecho irreversible, es probable que eso pase.
Hoy en día, la mayoría de las mediciones registran una diferencia de más de cinco puntos porcentuales entre el primer lugar (Andrés Manuel López Obrador) y el segundo (Roberto Madrazo o Felipe Calderón), pero son más las que tienden a cerrar la brecha de las preferencias entre los aspirantes.
La precisión no depende frecuentemente de la calidad o de la buena metodología, sino de la complejidad del contexto. Es decir, los «pollsters» o investigadores de opinión pública no podemos controlar el ambiente en que se dan los procesos y nuestra exactitud depende en buena medida de este. Si el proceso se enreda, las encuestas también se complican. Si la contienda se hace más competida y se cierra la diferencia entre las tres principales fuerzas electorales, las mediciones se verán en problemas.
El público y los medios de comunicación demandan que las encuestas no sólo den al ganador correcto sino que brinden el margen de victoria con precisión. En algún sentido las encuestas electorales han sido sobredimensionadas.
Los factores de inestabilidad
El escenario de 2006 se puede prever como inestable y, por lo tanto, difícil de medir. Baste observar el ejemplo del mes de octubre para detectar cómo en un periodo corto de tiempo suceden cantidad de eventos de alto impacto en la opinión pública, de tal manera que, dependiendo del momento en que se realizó cada una de estas mediciones, los porcentajes pueden variar sustancialmente.
En un solo mes vimos a un precandidato a la presidencia renunciar a sus aspiraciones (Arturo Montiel) a otro ganar la contienda electoral de su partido y convertirse en candidato (Calderón) y, durante todo este tiempo, la acción de una campaña negativa constante de la maestra Elba Esther Gordillo en contra del ahora candidato oficial del PRI, Roberto Madrazo.
A las dificultades de medición de octubre y noviembre hay que agregar el tema de las alianzas, que deben estar definidas a más tardar el 10 de diciembre próximo. En un escenario de elección presidencial cerrada, el peso específico de los partidos “pequeños” resultará fundamental. Si la diferencia entre la primera y la segunda fuerza electorales es de menos de cinco puntos porcentuales, la fuerza política que puede aportar dos puntos porcentuales al menos cobra gran importancia.
El Partido Verde Ecologista de México, Convergencia y Partido del Trabajo son los únicos entre los “pequeños” que pueden realizar alianzas, a diferencia de los partidos de reciente registro, como Nueva Alianza o Alternativa Socialdemócrata y Campesina, que obligatoriamente deben ir en solitario a la contienda federal de 2006.
Dado el porcentaje de votos que potencialmente aportarían, las alianzas apenas pueden mover ligeramente la balanza, pero tendrán gran influencia al final de la contienda. Las mediciones de octubre y noviembre van a cambiar una vez que estas uniones estén pactadas y haya candidatos registrados. Es decir, las primeras encuestas que considerarán todos los elementos de la contienda serán las que se levanten en enero y febrero.
Algunos de los peligros para las mediciones empezaron a vislumbrarse ya con las cuantificaciones de octubre y las primeras de noviembre. La falta de coincidencia y las diferencias sustanciales que se observan llaman la atención. Tal discrepancia con los resultados no se había registrado, probablemente, desde 2000.
Las últimas mediciones
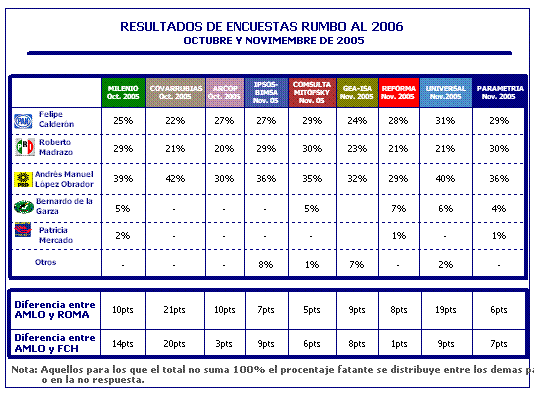
Dados los acontecimientos del último mes, las mediciones han diferido de manera considerable. Basta ver las últimas de Arcop, Covarrubias, Reforma (con dos mediciones), Ipsos-Bimsa, Demotecnia, Gea-Isa, Consulta-Mitofsky, El Universal y Parametría. En estas encuestas ya se observan contrastes importantes entre la primera y la segunda fuerza electoral (más de 19 puntos de discrepancia entre Covarrubias y Reforma). Otro dato importante es que no hay coincidencia para establecer cuál es la segunda fuerza electoral: Arcop, Covarrubias, El Universal y la segunda medición de Reforma ubican a Calderón en segundo lugar, mientras que el resto coloca en ese lugar a Madrazo.
Si bien estos datos son preocupantes, tal vez lo sea más que las tendencias no coincidan. Algunas mediciones señalan que López Obrador está subiendo, aunque para la mayoría de las encuestadoras viene a la baja, otras indican que Madrazo asciende, pero son más las que registran una caída del priísta. Coinciden en que Felipe Calderón va a la alza y que López Obrador es el puntero. Los problemas serios empezarían si en algún momento están en desacuerdo sobre quién va adelante.
Los investigadores de opinión vemos estos indicadores más como tendencias que como datos de precisión. Sin embargo, el público hace una lectura más crítica y evidentemente nota más las diferencias entre una medición y otra. Una forma de reducir las discrepancias de las encuestas que se reportan es excluir los datos extremos (outliers) y tomar el resto para ver qué tan similares son. En este caso sería necesario eliminar el informe más reciente de Reforma (su primer dato reportado en octubre tiene muy poca similitud con el reportado en noviembre) y el de Covarrubias y Asociados. Si se quitan estos dos, se observa mayor coincidencia entre las mediciones, y en general la mayoría dan una ventaja de López Obrador sobre la segunda fuerza de entre 5 y 10 puntos porcentuales.
Lamentablemente, aunque en análisis podamos dar el mismo valor a las mismas mediciones, hay algunas que son más influyentes y no es tan fácil excluirlas del análisis, aunque sean datos fuera de tendencia. Este es el caso de Reforma que, dada su visibilidad, tal vez debería ser más generoso con sus lectores y explicar las diferencias entre su primera y su segunda medición o por qué difiere tanto del resto. Con esta explicación, la sensación de caos en las mediciones tal vez se reduciría.
La historia
En el proceso electoral del 2000, las encuestas preelectorales dieron distintos ganadores de la contienda. Aunque algunas podrían ser defendibles técnicamente y tener resultados dentro del margen de error (Vicente Fox ganó por una diferencia de cinco puntos), la lectura generalizada fue que la mayoría de las mediciones erró en cuanto al vencedor.
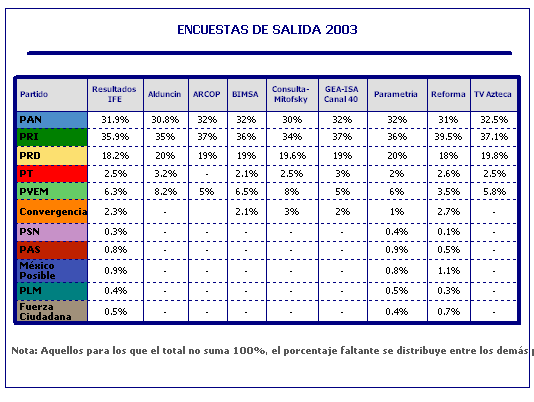
En 2003, las mediciones no coincidieron en el ganador, y dado el margen entre primera y segunda fuerza, la diferencia entre ganadores fue aún mayor. Por ejemplo, los datos de Reforma y GEA-ISA, dos colegas de la mejor reputación, no sólo estuvieron en desacuerdo en el triunfador, sino que entre una y otra mediciones hubo más de 13 puntos porcentuales de distancia.
En sentido estricto, si la diferencia es menor de cinco puntos para la elección presidencial de 2006, no nos deberían sorprender las diferencias en torno a quién será el ganador.
La técnica
Las encuestadoras independientes o de medios que son validables y confiables difícilmente pueden alejarse del número de mil entrevistas en una medición nacional. Realizar más tornaría estos proyectos financieramente poco viables; con una cantidad significativamente menor, los márgenes de error se ampliarían demasiado. Con este número de opiniones recolectadas el error teórico muestral sería de más menos tres puntos porcentuales. Con este nivel de riesgo cualquier diferencia menor de seis puntos porcentuales entre partidos estaría en los márgenes aceptables de error. Es decir, en el contexto de elección cerrada, cualquier diferencia menor a ese porcentaje, en sentido estricto, significaría un empate.
Este escenario sería muy similar al de la elección del 2003. En la última elección federal la diferencia entre el PRI y el PAN fue menor de cuatro puntos porcentuales. Eran más las mediciones nacionales que daban la victoria a uno u otro partido por menos de cinco puntos. Técnicamente y en sentido estricto, las encuestas estaban bien, el problema es que el ganador no siempre fue el que se indicaba.
Encuestas de salida
En defensa del gremio hay que decir que las encuestas de salida tanto en 2000, como en 2003 fueron muy precisas. En estás dos últimas elecciones la mayoría de quienes hicieron ejercicios de encuesta de salida fueron muy acertados. No hubo diferencia en ganadores, el orden de primero, segundo y tercer lugar coincidió y, en términos generales, las diferencias entre las tres principales fuerzas estuvieron bastante en línea.
Estos datos implican que de alguna manera, aunque se dieran discrepancias en las mediciones preelectorales, en las encuestas del día de la elección se medirá con precisión. Esta diferencia muy probablemente tiene que ver con una vulnerabilidad del contexto de los comicios. Cuando se mide antes de la jornada electoral se es vulnerable a cambios repentinos del entorno político, eventos de los últimos días, golpes de las campañas políticas, etcétera. Esto genera diferencias en las mediciones y las hace sensibles a los acontecimientos cotidianos de relevancia.
La normalidad
Es perfectamente normal que en democracias consolidadas, como sucedió en Estados Unidos durante la última elección, las encuestas se tomen como indicadores generales que ayudan a saber cuál puede ser un resultado probable de la elección y no se les lea como predicciones inequívocas. La contienda entre Bush y Kerry fue extraordinariamente cerrada y esto se sabía a partir de las mediciones realizadas. Algunos de estos ejercicios de opinión pública daban al presidente republicano Bush como ganador y otros al demócrata Kerry. Muchas encuestas dieron resultados erróneos.
En el contexto de esa elección las mediciones no podían dar más información que la de una contienda cerrada. El resultado final favoreció a Bush por menos de dos puntos porcentuales, como la mayor parte de las encuestas dijeron, aún las que no acertaron al ganador. Sin embargo, no por esto se cuestionó la utilidad de las mediciones.
Conclusión
Debemos estar concientes que el método de encuestas es vulnerable y por lo tanto nuestras mediciones de opinión serán imperfectas. Usarlas como propaganda o como profecías para anunciar o predecir lo que va a pasar termina por minar la credibilidad en el método. Es necesario dimensionar su utilidad, conocer sus límites y como sociedad hacer mejor uso de estos indicadores.
Esperar que las encuestas resuelvan las imperfecciones de nuestra democracia -como puede ser la debilidad de actores institucionales – es darles un papel que no les corresponde. Para bien o para mal, nuestro método es vulnerable, pero en algún sentido imprescindible para quienes toman decisiones y para la sociedad en general. Es fundamental entender su uso y sus límites.



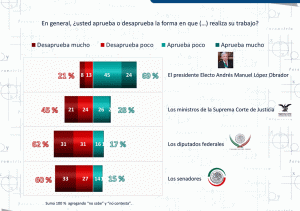
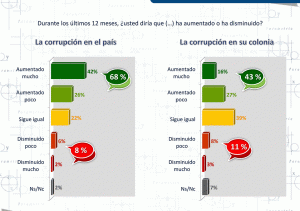
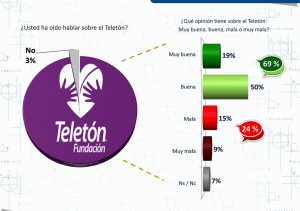
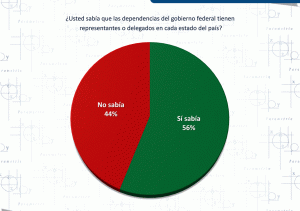


Deja un mensaje